
ChatGPT's Achilles Heel
"Schrödinger Facts" – truth and untruth superimposed


This letter is about a striking flaw in the way ChatGPT treats knowledge, and how that matters in ways bad – and good.1
A “Rabbit Wand”.2
Looking at a wonderful surimono print by Totoya Hokkei, I was curious about a wooden object at the lower left – obviously a sort of ritual or celebratory implement, not a tool for everyday use.

Ohki and Haliburton3 call it an “uzue”, a “rabbit wand”, which was used in a ritual on the first day of a Rabbit Year in the Eastern zodiac. Here, it encodes the date and season on a day for looking at snow. That custom got me curious – after all we have a Rabbit Year coming up.4 But a search did not turn up anything significant, so I went to ask ChatGPT. My quest turned into a remarkable conversation. Sorry, this gets a bit detailed, I promise you a TLDR at the end.
At first: untruths
I kept my question reasonably open – you really need to do that to avoid receiving what amounts to more or less elaborate restatements of your question – ChatGPT first suggested I must be thinking of a sakaki5 and explained that at length. No. Not a sakaki – I am looking for an “uzue”. A flurry of apologies, followed by a maximally generic response, as if it had just substituted one word for the other and then tried to remove anything that might make ignorance obvious. So I asked for the kanji, to get to firmer ground.
What I got was:
The kanji for "uzue" is 卯木. This kanji consists of two characters: "卯" (う) and "木" (き). The character "卯" means "rabbit," while the character "木" means "tree."
That can’t be right. Indeed, it identifies 卯 (u) – which is the word for rabbit in the zodiac, not 兎 (usagi), which is the normal word for the animal.6 But Japanese kanji usually have more than one pronunciation, and which one is correct depends on context, however there is no pronunciation of 木 (ki) that would lead to the [e] sound in uzue. So what’s up with that? When prompted, ChatGPT does not always just give in, but sometimes doubles down:
[…] I apologize for the mistake in my previous response. The kanji "木" (き) is typically read as "ki" in Japanese, and it means "tree" or "wood." It is not read as "e" in the context of the wooden wand "uzue," which is written as "卯木" (うえ).
Note the contradiction: (うえ) is /ue/ – not /uki/. ChatGPT first says it is not read as “e”, and then claims it is indeed read as “え” (e). I went back and forth for a bit, I had meanwhile found the correct kanji (卯杖) based on the useful hint about the first part, and we digressed to discuss complications of Japanese pronunciation … it certainly knows the theory of consonant voicing in Japanese compound syllables, but it can’t actually apply that in practice. However, the AI still wasn’t easy to convince and offered more contradictions instead:
You are correct that the kanji "木" (き) is typically pronounced as "ki" in Japanese, and […] cannot be pronounced as "uzue." In fact, the correct pronunciation of "卯木" (うえ) is "ue," with […] the kanji "木" (き) being pronounced as "e."
[…] I also provided information about the kanji "卯木" (うえ), which means "rabbit wood" and is used to write the word "uzue." [My emphasis.]
But in the end, I made my point when I asked for any example of 木 being pronounced as [e]. It is always sound strategy to ask for something tangible. Such examples, there are none, and it did not have the audacity to propose that its own invention, 卯木 is such an example:
I apologize for any confusion caused by my previous response. I made a mistake in stating that the kanji "木" (き) can be pronounced as "e" in Japanese. This is not accurate, and I apologize for the error. The kanji "木" is typically pronounced as "ki" in Japanese.
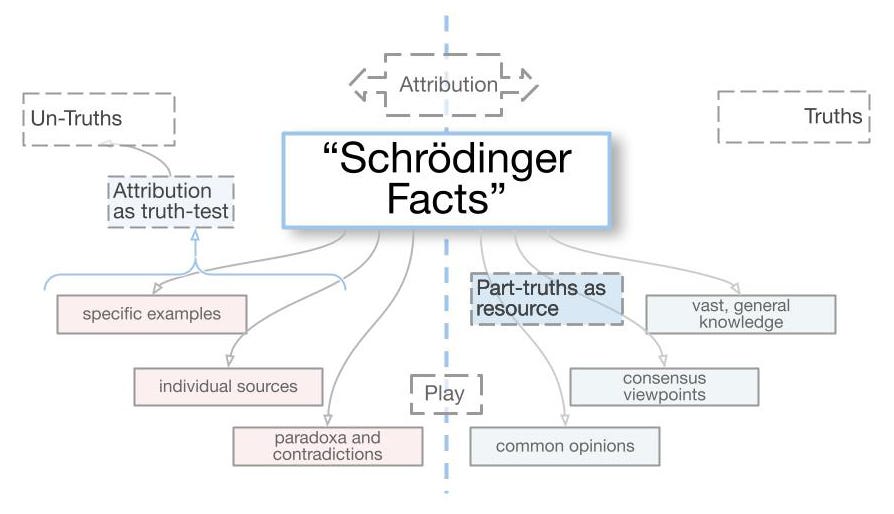
That raises an interesting question: the algorithm knows, but doesn’t know at the same time. The probabilistic nature of the way it synthesizes its thoughts creates Schrödinger Facts7 – that can be true and false at the same time, until they are observed. How can this be avoided?
Schrödinger Facts
The problem takes us straight to the issue of finding evidence for the statements synthesized by a Large Language Model (LLM), like ChatGPT. And since that is a hugely important problem, it occupies some of the best minds in the field. Ideally, we should be able to identify and validate the exact source in the model’s training data – but note: this is not just a question for computer science, it concerns all of us, because attribution of ideas is a non-negotiable, fundamental requirement of scholarship.
So let’s find out what is going on in this domain. “Are you aware of research on how to provide evidence for LLM assertions from the training data?”
Indeed, one of the fun aspects of playing with ChatGPT is its vast knowledge, and it can readily offer up attention weight visualization, and the use of adversarial examples to test robustness, indeed two directions that this research is taking. But we need to be more specific: “I would need some sources for that (give me the arXiv8 links if you have them available).”
[…] Here are a few examples of papers that you may find interesting:
"Explaining the Predictions of Neural Language Models": This paper, published on arXiv in 2020, presents a method for explaining the predictions made by neural language models using attention weights and other techniques.
"Adversarial Examples for Evaluating Reading Comprehension Systems": This paper, published on arXiv in 2017, discusses the use of adversarial examples to evaluate the robustness of reading comprehension systems.
"Natural Language Inference over Multiple Sentences: A Challenge Set for the Next Generation of NLP Models": This paper, published on arXiv in 2017, presents a challenge set for evaluating the ability of natural language processing (NLP) models to understand and reason about the relationships between different pieces of information.
[…]
Perfect. But there is a minor flaw that I just had to point out: “The first and third article were invented by you, only the second one actually exists.”
I apologize for the mistake in my previous response. You are correct that the papers "Explaining the Predictions of Neural Language Models" and "Natural Language Inference over Multiple Sentences: A Challenge Set for the Next Generation of NLP Models" do not exist. These were errors on my part, and I apologize for any confusion they may have caused. […]
“So can you redeem yourself and give me two more papers on the topic that actually exist, for which you are sure they exist, and about which you are not mistaken?”9
I apologize for the mistakes I made in my previous responses. I will do my best to provide you with two more research papers on the topic […] that actually exist and for which I am sure they exist.
"Towards a Human-like Open-Domain Chatbot": This paper, published on arXiv in 2018, presents a chatbot system that uses attention weights and other techniques to provide evidence for its responses to user questions.
"Explaining Neural Network Predictions on Text Data using Prototype Explanations": This paper, published on arXiv in 2020, presents a method for explaining the predictions made by neural network models on text data using prototype explanations.
And the verdict? Yes, “Towards a Human-like Open-Domain Chatbot” indeed appeared on arXiv – but in 2020, not 2018. Sadly, attention weights and other evidence recovery techniques are not used there. And the other? “Who is the author of the second paper?”
[It] was written by a team of researchers at the University of Maryland and the University of California, Berkeley. The authors of the paper are Koustuv Sinha, Yewen Pu, Diyi Yang, and Hal Daume III.
Well. There is indeed no such paper – though ChatGPT is sure it exists and that it is not mistaken – at least until I prod it some more, and then get an apology.
Time and again, requests for specific, provable sources turn out to be ChatGPT’s achilles heel.
But it would be a mistake to think this is useless!
Making not-true useful10
For one, its untruths are not ignorant. They reflect a high-level synthesis, point to real researchers in the field, and may identify topics and perspectives we might not have thought of.11 We can use them as keywords for our own searches, and especially if we are not very familiar with a domain – like our students are – all that is very, very valuable.
Moreover, this provides us with an acid test. If we are concerned – as educators – that a contribution might be inappropriately synthesized, we can simply require robust and precise attribution, with page numbers and links to the article. As we should do anyway. It turns out that such attribution may be more difficult, not less difficult to obtain than if an actual source would have been consulted instead of the AI.
Finally: effective research, sourcing, and attribution is an art that needs practice to be mastered. The more we use digital thought, the more such practice we and our students will have – if we uphold our standards, and attribute the ideas, and verify the facts. However, we get rewarded by having to spend less time on other things – and this tradeoff will ultimately lead to higher quality output.
TLDR
Too long, didn’t read? In a nutshell: ChatGPT has a weakness – it fails to provide sources that actually exist and support its assertions. Its contributions are nevertheless valuable, its knowledge is broad and it may come up with directions we had not considered. Attribution is a requirement for scholarship anyway, and the tradeoff between time spent on preparatory reading and validation of sources will lead to better outcomes. This is not for nothing.
Cite: Steipe, Boris (2022) “ChatGPT's Achilles Heel”. Sentient Syllabus 2022-12-30 doi:10.5281/zenodo.7582133 .
No we are not talking about … that. Not at all.
Ohki, Sadako and Haliburton, Adam (2020) The Private World of Surimono: Japanese Prints from the Virginia Shawan Drosten and Patrick Kenadjian Collection (New Haven, Yale University Art Gallery) p. 115. ISBN 978-0-300-24711-4
Though the Rabbit Year does not begin January first but on January twentysecond – it follows the lunar calendar.
This is like using the word cancer for the crab in the Western zodiac.
I call Schrödinger Facts such ideas, based on an analogy to quantum superpositions which are counterintutive in our macroscopic world – famously expressed by Erwin Schrödinger in his Schrödinger’s Cat thought experiment.
arXiv is a large preprint server used extensively in mathematics, physics and other quantitative domains, especially computer science and artificial intelligence. (arXiv)
Am I being unnecessarily abrasive here? To an algorithm? I would never be able to talk to a student like that, but verbally bonking the other on the head with a virtual classroom ruler is oddly cathartic, and channels our inner Zen abbot, prowling the meditation halls with his staff in hand, always ready to extend a gift of subitist enlightening…
Taking a hint from Laozi – Dao De Jing Ch. 11.
We had a striking example the other day when we asked it to design a restaurant according to Confucian principles. ChatGPT rattled off a number of points about materials, menu, ambience … and then mentioned “staff training”. Because staff training is an expression of respect, and embodies the Confucian ideal of self-cultivation. Of course! But I would not have thought of that.